
바이브코딩 AI 모델 선택 가이드 - 언제 어떤 모델을 써야할까?
데이터베이스 스키마 설계 같은 중요한 작업에 Opus 같은 프리미엄 AI 모델을 언제 사용해야 하는지, 그리고 더 나은 결과를 위해 AI 모델 선택을 최적화하는 방법을 알아보세요.
모든 작업에 최고급 AI 모델이 필요한 건 아니다
"이 작업은 중요하므로 Opus 모델을 사용합니다."
AI 코딩 도구를 사용하다 보면 이런 고민에 빠지곤 합니다. "단순한 CRUD API를 만드는데도 Opus를 써야 할까?" "간단한 유틸리티 함수 하나 만드는데 비싼 모델을 쓰는 게 맞나?"
현실적인 질문입니다. GPT-4, Claude Opus, Gemini Pro 같은 프리미엄 AI 모델은 성능이 뛰어나지만 비용도 만만치 않습니다. 모든 작업에 최고급 모델을 쓰는 건 마치 편의점 가는데 스포츠카를 몰고 가는 것과 같습니다.
그런데 어떤 작업은 반드시 좋은 모델을 써야 합니다.
데이터베이스 스키마 설계가 대표적입니다. 스키마를 한 번 잘못 잡으면 나중에 전체를 뜯어고쳐야 합니다. 테이블 구조를 바꾸면 API도, 프론트엔드 로직도, 심지어 비즈니스 로직까지 연쇄적으로 수정해야 하죠. 프로젝트가 커질수록 리팩토링 비용은 기하급수적으로 증가합니다.
아키텍처 결정도 마찬가지입니다. 모놀리스로 갈지 마이크로서비스로 갈지, 상태 관리를 어떻게 할지, 인증 시스템을 어떻게 구성할지. 이런 결정은 프로젝트 전체의 방향을 좌우합니다.
중요한 건 '언제' 좋은 모델을 써야 하는지 아는 것입니다. 이 글에서는 실제 데이터베이스 설계 과정을 예시로, 프리미엄 AI 모델을 효과적으로 활용하는 방법을 알아보겠습니다.
좋은 AI 모델을 써야 하는 작업들

모든 개발 작업이 동일한 가치를 가지는 건 아닙니다. 어떤 작업은 나중에 쉽게 바꿀 수 있지만, 어떤 작업은 한 번 결정하면 되돌리기 어렵습니다.
프리미엄 모델이 필요한 작업
1. 데이터베이스 스키마 설계
데이터베이스는 애플리케이션의 뼈대입니다. 스키마 설계는 단순히 테이블과 컬럼을 정의하는 것이 아닙니다:
- 데이터 무결성: 외래키 관계, 제약조건, 인덱스 전략
- 확장성: 미래의 기능 추가를 고려한 유연한 구조
- 정규화 vs 비정규화: 성능과 데이터 일관성의 균형
- 마이그레이션 전략: 스키마 변경 시 기존 데이터 처리
단순한 스키마는 GPT-3.5나 Gemini Flash로도 가능합니다. 하지만 복잡한 비즈니스 로직이 얽힌 스키마는 다릅니다. Opus나 GPT-4 같은 프리미엄 모델은 다음을 고려합니다:
- 데이터 플로우 전체를 파악하여 최적의 테이블 구조 제안
- MVP 출시를 위한 최소 필수 엔티티 도출
- 나중에 추가될 기능을 고려한 확장 가능한 설계
2. 아키텍처 결정
시스템 아키텍처는 변경하기 가장 어려운 부분입니다:
- 모놀리스 vs 마이크로서비스
- 서버 vs 서버리스
- SQL vs NoSQL
- RESTful vs GraphQL vs tRPC
잘못된 아키텍처 선택은 개발 속도를 늦추고, 유지보수를 어렵게 하며, 확장성을 제한합니다. 프리미엄 모델은 프로젝트의 규모, 팀 구성, 예상 트래픽을 종합적으로 고려하여 최적의 아키텍처를 제안합니다.
3. 복잡한 비즈니스 로직 설계
결제 시스템, 권한 관리, 워크플로우 엔진 같은 복잡한 비즈니스 로직은 보안, 성능, 예외 처리를 모두 고려해야 합니다. 단순한 모델은 주요 케이스만 처리하지만, 프리미엄 모델은 엣지 케이스와 보안 취약점까지 고려합니다.
일반 모델로 충분한 작업
반면 이런 작업들은 가벼운 모델로도 충분합니다:
- 단순 CRUD API 생성: 패턴이 명확한 반복 작업
- UI 컴포넌트 코딩: 기존 디자인 시스템을 따르는 작업
- 유틸리티 함수: 명확한 입출력이 있는 단순 로직
- 테스트 코드 작성: 명세가 이미 정의된 경우
이런 작업은 GPT-3.5, Gemini Flash, 또는 무료 AI 모델로도 충분히 처리할 수 있습니다. 비용 대비 효과를 고려하면 오히려 이런 작업에 프리미엄 모델을 쓰는 게 낭비일 수 있습니다.
핵심은 균형입니다. 중요한 설계는 프리미엄 모델로, 반복적인 구현은 일반 모델로. 이렇게 하면 비용을 절약하면서도 프로젝트 품질을 유지할 수 있습니다.
데이터베이스 설계 실전 프로세스
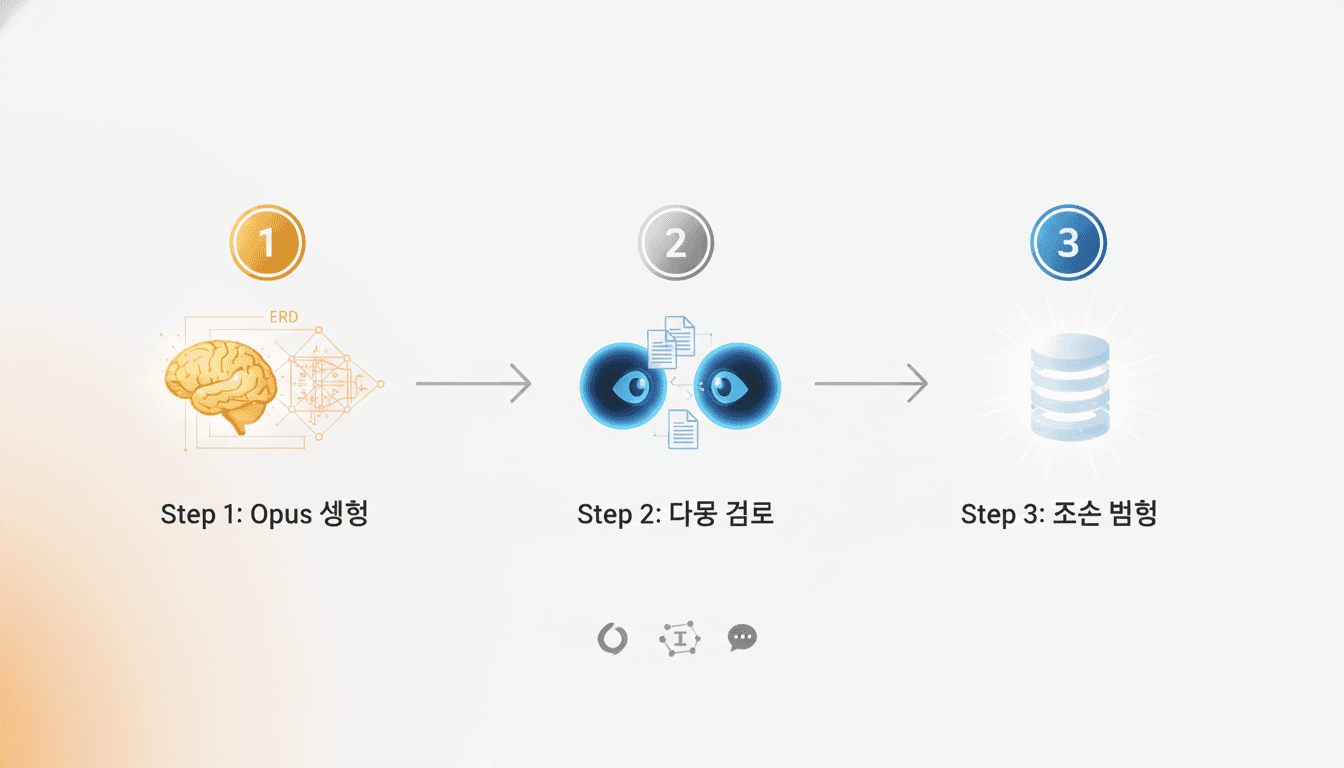
이론은 충분합니다. 이제 실제로 어떻게 하는지 보겠습니다. 커서맛피아가 라이브 바이브 코딩에서 선보인 프로세스를 단계별로 살펴보겠습니다.
Step 1: Opus로 데이터 플로우 및 스키마 생성
첫 단계는 AI에게 명확한 지시를 내리는 것입니다. 모호한 요청이 아니라 구체적인 컨텍스트를 제공해야 합니다:
프롬프트 예시:
에이전트 모드로 전환하여 프로젝트 전체 데이터 플로우를 상세히 기획하고,
이에 맞춘 데이터베이스 스키마를 erd.md 파일로 생성해주세요.
프로젝트 컨텍스트:
- 서비스명: [서비스명]
- 핵심 기능: [기능 목록]
- 사용자 유형: [일반 사용자, 관리자 등]
- 주요 데이터 흐름: [로그인 → 대시보드 → 작업 생성 → 완료]
요구사항:
1. MVP 출시에 필수적인 최소 엔티티만 포함
2. 향후 확장 가능한 구조
3. 각 엔티티 간 관계를 명확히 정의
4. Mermaid 다이어그램으로 시각화
Opus는 이 지시를 받으면:
- 전체 데이터 플로우를 분석합니다
- 핵심 엔티티를 도출하고 각 엔티티의 필드를 정의합니다
- 관계(1:1, 1:N, N:M)를 설정합니다
- Mermaid ERD 다이어그램을 생성합니다
- 각 테이블의 목적과 설계 의도를 문서화합니다
생성된 erd.md 파일을 열면 Mermaid 차트가 자동으로 렌더링됩니다. 시각적으로 전체 스키마 구조를 확인할 수 있죠.
Step 2: 다른 AI로 검토 (클렌징)
Opus가 생성한 결과가 완벽할까요? 아닙니다. 한 번 더 검증이 필요합니다. 여기서 다중 모델 검증 전략을 사용합니다.
Gemini로 검토:
생성된 스키마를 Gemini로 가져가 다음과 같이 요청합니다:
이 데이터베이스 스키마를 검토해주세요.
검토 관점:
- MVP 출시를 위한 최소 스펙인가?
- 불필요하게 복잡한 구조는 없는가?
- 빠른 출시 중심의 실용적인 설계인가?
- 제거해도 되는 엔티티나 필드는?
Gemini는 실용성과 단순함에 초점을 맞춰 검토합니다. "이 필드는 나중에 추가해도 됩니다", "이 관계는 초기 버전에서 불필요합니다" 같은 피드백을 줍니다.
ChatGPT로 이중 검증:
동일한 프롬프트를 ChatGPT에도 입력합니다. 왜 두 개의 AI로 검토할까요?
- 다른 관점: 각 모델은 조금씩 다른 우선순위를 가집니다
- 맹점 발견: 한 모델이 놓친 문제를 다른 모델이 찾을 수 있습니다
- 균형잡힌 결정: 두 모델의 공통 의견은 신뢰도가 높습니다
실제 경험상, Gemini는 "최소화"에 집중하고, ChatGPT는 "안정성"에 집중하는 경향이 있습니다. 두 의견을 종합하면 실용적이면서도 안정적인 스키마를 얻을 수 있습니다.
Step 3: 검토 결과 반영
이제 받은 피드백을 바탕으로 스키마를 수정합니다:
프롬프트 예시:
Gemini의 검토 결과를 반영하여 데이터베이스 스키마를 수정해주세요.
주요 변경사항:
- [Gemini가 제안한 변경사항 1]
- [Gemini가 제안한 변경사항 2]
- [ChatGPT가 제안한 변경사항]
수정된 스키마를 erd.md 파일에 업데이트하고 저장해주세요.
이 과정을 거치면:
- 불필요한 복잡성 제거: MVP에 필요 없는 테이블과 필드 삭제
- 성능 최적화: 인덱스 전략 개선
- 확장성 확보: 미래 기능을 위한 여지는 남겨둠
실제 사례:
한 프로젝트에서 Opus는 사용자 권한 시스템을 5개 테이블로 설계했습니다. Gemini 검토 후 MVP에는 2개 테이블만으로 충분하다는 결론을 얻었습니다. 나머지 3개는 나중에 추가하기로 했죠. 덕분에 개발 기간을 2주 단축할 수 있었습니다.
룰 직접 참조의 중요성

프리미엄 모델을 쓴다고 자동으로 좋은 결과가 나오는 건 아닙니다. AI에게 충분한 컨텍스트를 제공해야 합니다.
커서 룰이 바로 참조되지 않을 수 있다
Cursor나 다른 AI 코딩 도구를 사용할 때 .cursorrules 파일에 프로젝트 규칙을 정의합니다:
// .cursorrules 예시
데이터베이스: PostgreSQL
ORM: Prisma
네이밍 컨벤션: snake_case
인덱스 전략: 자주 조회되는 컬럼에 인덱스 추가
문제는 AI가 항상 이 룰을 자동으로 참조하지 않는다는 점입니다. 특히 복잡한 작업일수록 AI는 일반적인 베스트 프랙티스에 의존할 수 있습니다.
중요한 작업일수록 룰을 명시적으로 언급하라
데이터베이스 스키마 같은 중요한 작업을 할 때는 직접 룰을 참조하도록 요청하세요:
프롬프트 예시:
.cursorrules 파일의 규칙을 참조하여 데이터베이스 스키마를 생성해주세요.
특히 다음 사항을 반드시 준수:
- 테이블명과 컬럼명은 snake_case 사용
- UUID를 기본키로 사용
- created_at, updated_at 타임스탬프 필드 자동 추가
- soft delete를 위한 deleted_at 필드 포함
이렇게 하면:
- 일관성: 프로젝트 전체 규칙과 일치하는 스키마
- 호환성: 기존 코드베이스와 매끄럽게 통합
- 표준화: 팀 내 코딩 스타일 유지
프로젝트별 CLAUDE.md 활용
더 나아가 프로젝트 루트에 CLAUDE.md 파일을 만들어 AI 전용 가이드를 제공할 수 있습니다:
# CLAUDE.md
## 데이터베이스 설계 가이드
### 필수 사항
- 모든 테이블에 UUID 기본키
- soft delete 패턴 사용
- 타임스탬프 자동 관리
### 권장 사항
- 정규화를 우선하되 성능 필요 시 비정규화
- JSON 컬럼은 PostgreSQL jsonb 타입 사용
- 관계는 외래키로 명시적 정의
### 금지 사항
- Integer 기본키 사용 금지
- Cascade delete 사용 금지 (soft delete 사용)
중요한 작업을 시작할 때:
CLAUDE.md의 데이터베이스 설계 가이드를 참조하여
스키마를 생성해주세요.
이렇게 명시적으로 요청하면 AI는 프로젝트별 규칙을 정확히 따릅니다.
컨텍스트가 결과를 결정한다
같은 Opus 모델이라도:
- 컨텍스트 없음: 일반적인 스키마 생성
- 컨텍스트 있음: 프로젝트에 최적화된 맞춤형 스키마 생성
프리미엄 모델의 진가는 충분한 컨텍스트를 제공했을 때 나타납니다.
Vooster AI로 체계적인 AI 모델 활용하기
이제 실전입니다. Vooster AI는 AI 모델 선택과 데이터베이스 설계를 체계적으로 도와줍니다.
AI 모델 선택 옵션 (FREE/PRO/MAX)
Vooster AI는 작업의 중요도에 따라 세 가지 AI 모델 등급을 제공합니다:
FREE 모델:
- Gemini Flash 같은 빠르고 가벼운 모델
- 단순 태스크 생성, 간단한 문서 업데이트
- 크레딧 소비 없음
PRO 모델:
- GPT-4 미니, Claude Sonnet 수준
- 일반적인 PRD 생성, 태스크 분해
- 적절한 크레딧 비용 (10-15 크레딧)
MAX 모델:
- Claude Opus 4.5, GPT-4 같은 최고급 모델
- 데이터베이스 ERD 생성 (크레딧: 20)
- 아키텍처 설계, 복잡한 기술 명세 작성
- 중요한 의사결정이 필요한 작업
프로젝트를 시작할 때 모델 등급을 선택하면, 각 작업에 자동으로 적절한 모델이 할당됩니다.
ERD 자동 생성 기능
Vooster AI의 AI PM 에이전트와 대화하면 자동으로 ERD를 생성합니다:
- 프로젝트 정보 수집: 서비스 설명, 핵심 기능, 사용자 유형
- 데이터 플로우 분석: Technical Architect AI가 전체 흐름 파악
- ERD 자동 생성: MAX 모델(Opus)로 최적의 스키마 생성
- Mermaid 시각화: ERD 다이어그램을 문서에서 바로 확인
생성된 ERD는 erd.md 문서에 저장되며, Vooster AI 대시보드에서 바로 시각화됩니다.
문서별 AI 챗으로 대화형 수정
생성된 ERD가 마음에 들지 않으면? 문서별 AI 챗 기능으로 바로 수정할 수 있습니다:
채팅 예시:
User: 사용자 권한 테이블을 더 단순하게 만들어줘.
MVP에는 admin과 user 두 가지 역할만 필요해.
AI: 알겠습니다. Role 테이블을 제거하고 User 테이블에
role enum 필드를 추가하는 것으로 단순화하겠습니다.
[ERD 업데이트됨]
User: 좋아. 그리고 이메일 인증 기능을 위한 필드도 추가해줘.
AI: verified_at timestamp와 verification_token을
User 테이블에 추가했습니다. [ERD 업데이트됨]
대화하듯이 스키마를 개선할 수 있습니다. AI가 변경사항을 즉시 반영하고 문서를 업데이트합니다.
MCP 연동으로 개발 중 ERD 참조
Vooster AI는 MCP(Model Context Protocol)로 Cursor, Claude Code 같은 AI 코딩 도구와 연동됩니다:
// Cursor에서 개발 중
"Vooster AI의 ERD 문서를 참조하여 Prisma 스키마를 생성해줘"
AI 코딩 도구가 자동으로 Vooster AI에서 ERD를 가져와 Prisma 스키마로 변환합니다. 설계와 구현이 완벽하게 동기화됩니다.
Vooster AI의 장점:
- 중요한 작업(ERD)은 자동으로 MAX 모델 사용
- 일반 작업(태스크 업데이트)은 FREE/PRO 모델로 비용 절약
- 모든 문서가 프로젝트 컨텍스트로 연결되어 일관성 유지
- MCP로 설계와 코딩이 끊김없이 이어짐
결론: 전략적으로 AI 모델을 선택하라
데이터베이스 스키마 하나 잘못 잡으면 나중에 전체를 뜯어고쳐야 합니다. 중요한 설계에 값싼 모델을 쓰는 건 단기적으로는 비용을 절약하는 것 같지만, 장기적으로는 훨씬 더 큰 비용을 초래합니다.
반대로 모든 작업에 프리미엄 모델을 쓰는 것도 낭비입니다. 간단한 CRUD 함수 만드는데 Opus를 쓸 필요는 없죠.
전략적으로 AI 모델을 선택하세요:
-
중요한 설계: 데이터베이스, 아키텍처, 보안 → MAX 모델 (Opus, GPT-4)
-
일반 개발: PRD, 태스크 분해, 문서 작성 → PRO 모델 (Sonnet, GPT-4 mini)
-
반복 작업: CRUD 생성, 단순 함수 → FREE 모델 (Gemini Flash)
-
다중 모델 검증: 중요한 결과는 다른 AI로 한 번 더 검토
-
명시적 컨텍스트 제공: 룰 파일을 직접 참조하도록 지시
Vooster AI는 이 모든 과정을 자동화합니다:
- 작업 중요도에 따라 자동으로 적절한 AI 모델 선택
- ERD 같은 중요한 문서는 MAX 모델로 생성
- 문서별 AI 챗으로 대화형 수정
- MCP 연동으로 설계와 코딩이 끊김없이 연결
중요한 설계에는 Vooster AI의 MAX 모델을 활용하세요. 프로젝트의 기초를 튼튼하게 다지면, 나머지 개발은 자연스럽게 따라옵니다.
좋은 코드는 좋은 설계에서 시작됩니다. 지금 Vooster AI와 함께 체계적인 바이브 코딩을 시작하세요 →
체계적인 바이브코딩을 시작하세요
PRD 생성부터 기술 설계, 태스크 생성까지 Vooster가 책임집니다.
PRD 생성
상세한 요구사항 문서 자동 생성
기술 설계
구현 계획 및 아키텍처 설계
태스크 생성
개발 태스크 자동 분해 및 관리
신용카드 불필요 · 무료로 모든 기능 체험
관련 포스트

1시간 안에 서비스 기반 만들기 - 실전 바이브 코딩
체계적인 아키텍처와 AI 기반 계획으로 60분 안에 완전한 서비스 기반을 구축하는 바이브 코딩 실전 가이드

수익을 내는 소프트웨어를 만드는 6단계 (초보 → 프로)
개발자 고용부터 AI 에이전트 협업까지, 수익을 내는 소프트웨어를 만드는 6단계를 알아보세요. 자신의 레벨에 맞는 도구로 바이브 코딩을 시작하세요.

Y Combinator 스타트업 25%가 AI로 코드 95% 생성, 그런데 왜 실패할까?
바이브 코딩 혁명 속에서도 AI 프로젝트가 실패하는 이유를 알아보세요. AI 시대에 체계적인 문서화가 왜 더 중요해졌는지 확인하세요.